
Databricks is a cloud-based data engineering platform that enables data engineers, data scientists, and data analysts to collaborate on data-driven projects. Founded by the original creators of Apache Spark, Databricks provides a scalable, secure, and intuitive environment for working with large-scale data sets.
Key Features of Databricks
1. Data Engineering
- Data Ingestion: Databricks supports various data sources, including AWS S3, Azure Blob Storage, Google Cloud Storage, and on-premises data warehouses.
- Data Processing: Utilize Apache Spark for distributed processing and transformation of large data sets.
- Data Storage: Store data in Databricks’ managed delta lake, which provides versioning, security, and performance.
2. Data Science and Analytics
- Notebooks: Collaborative notebooks for data exploration, visualization, and machine learning.
- Visualizations: Built-in support for popular visualization libraries like Matplotlib, Seaborn, and Plotly.
- Machine Learning: Integrated support for popular ML libraries like scikit-learn, TensorFlow, and PyTorch.
3. Collaboration and Governance
- Multi-User Support: Real-time collaboration and version control.
- Access Control: Granular access control and permission management.
- Audit Logs: Track user activity and changes.
4. Security and Compliance
- Encryption: Data encryption at rest and in transit.
- Network Security: VPC support and firewall configurations.
- Compliance: Meets various compliance standards, including HIPAA, GDPR, and SOC 2.
5. Integration and Extensibility
- APIs: REST APIs for integrating with custom applications.
- Partnerships: Integrations with popular tools like Tableau, Power BI, and Qlik.
- Extensions: Support for custom extensions and plugins.
Benefits of Using Databricks
- Scalability: Handle large-scale data sets with ease.
- Collaboration: Streamline data-driven projects across teams.
- Flexibility: Support for various data sources, formats, and processing engines.
- Security: Robust security features for sensitive data.
- Cost-Effectiveness: Pay-as-you-go pricing model.
Use Cases for Databricks
1. Data Warehousing: Build Scalable Data Warehouses
Databricks enables organizations to build scalable data warehouses, integrating data from various sources and providing a centralized repository for analytics. Key benefits include:
- Unified view of data across the organization
- Scalability to handle large data volumes
- Support for various data formats (e.g., CSV, JSON, Avro)
- Integration with business intelligence tools (e.g., Tableau, Power BI)
- Improved data governance and security
Example: A retail company uses Databricks to build a data warehouse, combining sales data from online and offline channels, customer information, and supply chain data.
2. Data Lakes: Create Managed Delta Lakes for Data Storage
Databricks’ delta lake provides a scalable, secure, and managed repository for storing raw and processed data. Key benefits include:
- Scalable storage for large data volumes
- Data versioning and history
- ACID transactions for data consistency
- Integration with Apache Spark for processing
- Support for various data formats
Example: A financial institution uses Databricks to create a delta lake, storing transactional data, customer information, and market data.
3. Real-Time Analytics: Enable Real-Time Analytics and Reporting
Databricks enables real-time analytics and reporting through its streaming capabilities and integration with Apache Spark. Key benefits include:
- Real-time insights into business operations
- Improved decision-making
- Scalability to handle high-velocity data streams
- Integration with visualization tools (e.g., Tableau, Power BI)
- Support for event-driven architectures
Example: An e-commerce company uses Databricks to analyze customer behavior in real-time, enabling personalized recommendations and improving customer experience.
4. Machine Learning: Train and Deploy ML Models
Databricks provides a collaborative environment for data scientists to train, deploy, and manage machine learning models. Key benefits include:
- Scalable infrastructure for model training
- Integration with popular ML libraries (e.g., scikit-learn, TensorFlow)
- Model deployment and serving
- Collaboration and version control
- Support for automated hyperparameter tuning
Example: A healthcare organization uses Databricks to develop predictive models for patient outcomes, leveraging electronic health records and genomic data.
5. Data Integration: Integrate Disparate Data Sources
Databricks enables organizations to integrate disparate data sources, providing a unified view of data across the organization. Key benefits include:
- Integration of structured, semi-structured, and unstructured data
- Support for various data sources (e.g., relational databases, NoSQL databases, cloud storage)
- Scalability to handle large data volumes
- Improved data quality and governance
- Real-time data synchronization
Example: A logistics company uses Databricks to integrate data from sensors, GPS trackers, and supply chain management systems, improving route optimization and delivery times.
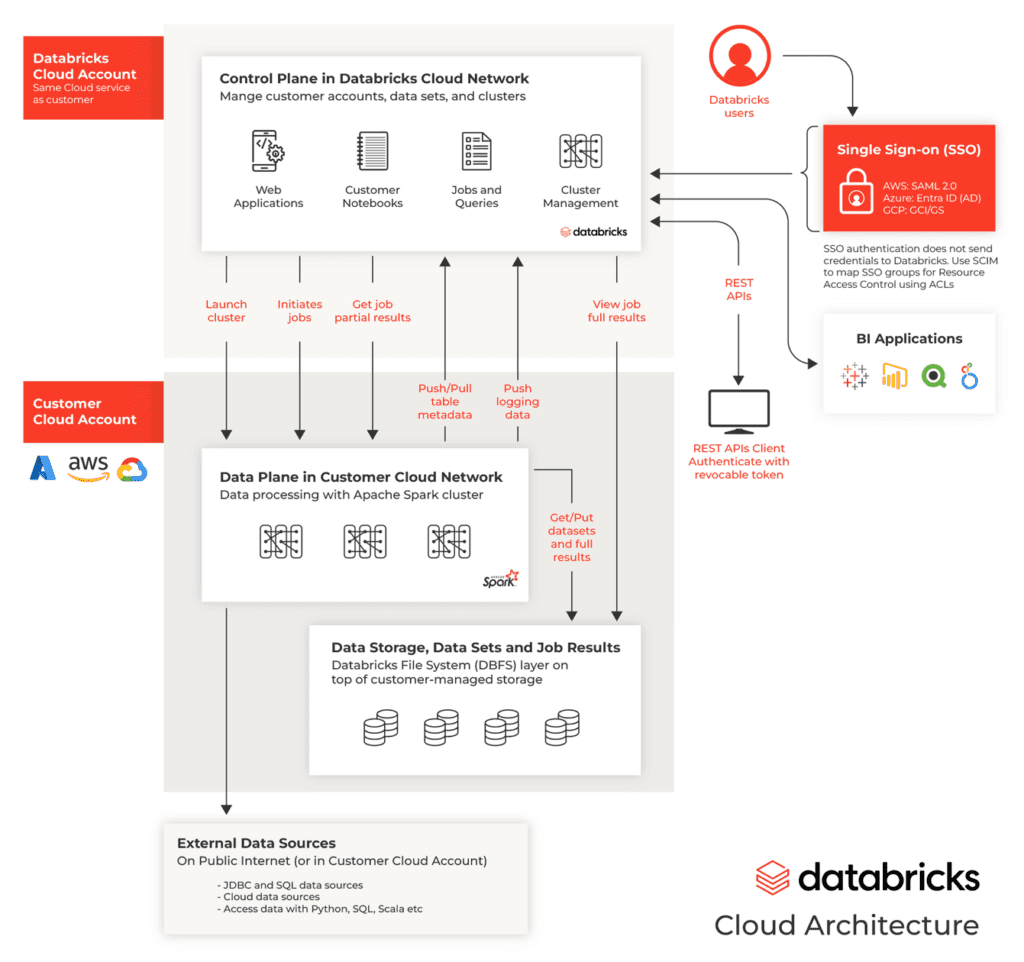
Databricks Architecture
Databricks’ architecture consists of:
- Databricks Cluster: Scalable, managed clusters for data processing.
- Databricks File System (DBFS): Managed file system for data storage.
- Databricks Delta Lake: Managed delta lake for data storage and versioning.
- Apache Spark: Distributed processing engine.
Databricks Tools and Integrations
- Databricks CLI: Command-line interface for automation.
- Databricks APIs: REST APIs for integration.
- Databricks Connect: Integration with popular tools like Tableau.
- Databricks Partner Ecosystem: Integrations with industry-leading tools.
Databricks Pricing
Databricks offers various pricing plans:
- Standard: Pay-as-you-go pricing.
- Premium: Additional features and support.
- Enterprise: Custom pricing for large-scale deployments.
